こんな感じのデータフレームがあったとして
import numpy as np
import pandas as pd
import os
df = pd.DataFrame([{'col_0': "A", 'col_1': 1, 'col_2': np.nan},
{'col_0': "A", 'col_1': 4, 'col_2': 5},
{'col_0': "B", 'col_1': 7, 'col_2': 8},
{'col_0': "B", 'col_1': 9, 'col_2': 6}])
df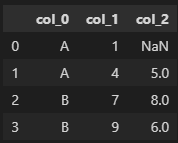
col_0の値ごとにシートを分けてexcelに保存したいとする。
そんなときのソース。
mode=’a’というのがポイント。appendのa
# Cドライブ直下の場合(保存場所は任意のパスに変更)
dir='C:\'
sheet_names = df['col_0'].unique().tolist()
savename = os.path.join("dir", "hogehoge.xlsx")
if os.path.exists(savename):
os.remove(savename)
for sheet_name in sheet_names:
cdf = df.query('col_0 == @sheet_name')
if os.path.exists(savename):
with pd.ExcelWriter(savename, engine="openpyxl", mode="a") as writer:
cdf.to_excel(writer, sheet_name=sheet_name, index=False)
else:
with pd.ExcelWriter(savename, engine="openpyxl") as writer:
cdf.to_excel(writer, sheet_name=sheet_name, index=False)
